Imagine you are building a feature that needs to fetch data from 100 different API endpoints. You write a clean, simple loop in Python to call each endpoint one after the other. Each request takes exactly 1 second to respond.
You run the script, grab a cup of coffee, and wait. It takes over 100 seconds to finish.
Your code spends 99% of its time doing absolutely nothing. It is just sitting there, waiting for the remote servers to send back data over the network. This feels incredibly slow, and your users will definitely notice.
Many developers encounter this exact performance bottleneck early in their careers. To fix it, you need your program to handle multiple tasks at the same time. This is where Python concurrency comes into play.
Python gives us three distinct tools to solve this problem: threading, multiprocessing, and asyncio. However, choosing the wrong tool can actually make your code slower and significantly more complicated.
Most developers discover the Global Interpreter Lock (the GIL) shortly after wondering why their threaded code somehow became more complicated without becoming any faster.
In this article, we will break down how these three concurrency models work from first principles, look at real benchmarks, and learn exactly how to choose the right tool for your specific backend systems.
What Is Concurrency?
Before we look at code, we need to clear up a massive point of confusion. Developers often use the words concurrency and parallelism interchangeably, but they mean entirely different things.
Concurrency is about structure. It means organizing your program so it can handle multiple tasks at the same time. A concurrent program makes progress on multiple tasks, but it is not necessarily running them at the exact same millisecond.
Parallelism is about execution. It means actually executing multiple tasks at the exact same physical millisecond. This requires a computer with multiple CPU cores.
Let us use a simple analogy.
Imagine a single customer support agent handling three different live chats. The agent types a reply to Chat A, waits for the user to type back, switches to Chat B to answer a quick question, and then checks on Chat C. The agent is handling three chats concurrently. But at any single microsecond, the agent is only typing on one keyboard.
Now imagine three different customer support agents sitting at three different desks, each handling their own single chat. That is parallelism. The tasks are happening completely independently and simultaneously.
In Python, the way we achieve concurrency depends entirely on whether our code is waiting on external resources or maxing out our CPU.
A Baseline Sequential Program
To understand how concurrency helps, we first need a baseline. Let us write a simple, traditional program that runs sequentially (one task after another).
We will simulate a slow network request using time.sleep().
import time
def fetch_data(task_id):
print(f"Starting task {task_id}")
# Simulating a 1-second network delay
time.sleep(1)
print(f"Finished task {task_id}")
def main():
start_time = time.time()
# Run 5 tasks sequentially
for i in range(1, 6):
fetch_data(i)
end_time = time.time()
print(f"Total execution time: {end_time - start_time:.2f} seconds")
if __name__ == "__main__":
main()
Expected Output:
Starting task 1
Finished task 1
Starting task 2
Finished task 2
Starting task 3
Finished task 3
Starting task 4
Finished task 4
Starting task 5
Finished task 5
Total execution time: 5.00 seconds
Why This Program Is Slow
Every time the loop calls fetch_data(), the entire execution of the program stops dead in its tracks at time.sleep(1). The operating system halts the Python process for a full second. Your CPU sits idle, doing absolutely zero useful work while waiting for the timer to tick down.
Because we have 5 tasks, and each task must wait for the previous one to finish completely, the total time is simply the sum of all wait times (just over 5 seconds).
Understanding Threading
A thread is the smallest unit of execution that an operating system can schedule. Think of a thread as a single train of thought within your program.
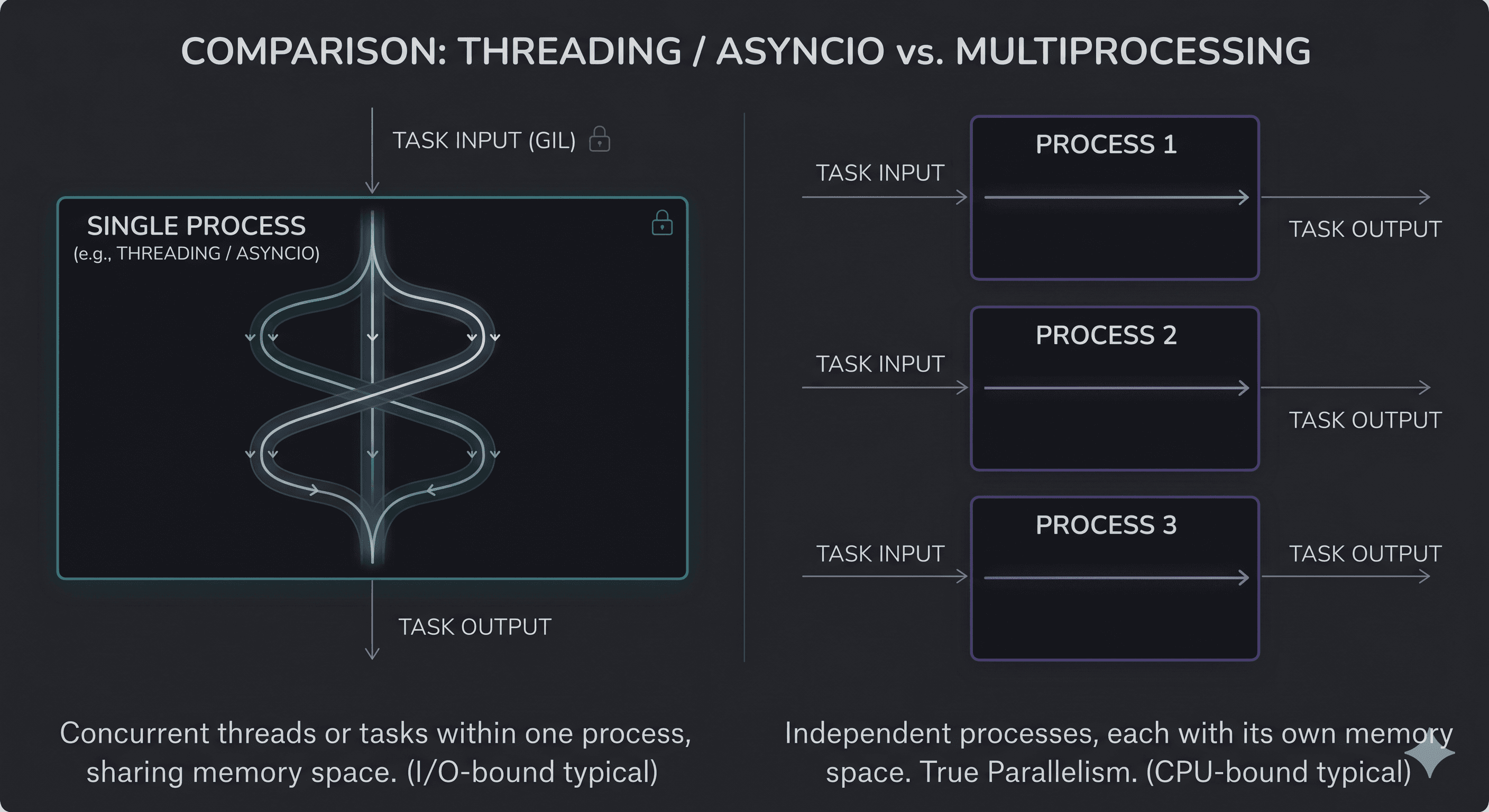
When you run a standard Python script, it runs inside a single process and executes on a single main thread. However, your program can ask the operating system to spin up additional threads.
All threads inside a single process share the exact same memory space. This means they can easily access the same variables, objects, and data structures.
Because threads share memory, switching between them is incredibly fast for the operating system. This process of switching attention from one thread to another is called context switching.
Threading shines when your program is I/O-bound (Input/Output bound). An I/O-bound task is any task where the bottleneck is waiting for something outside your CPU, such as:
Waiting for a response from a third-party API
Waiting for a database query to finish
Reading or writing a file to a hard drive
Let us rewrite our sequential program using Python's modern ThreadPoolExecutor from the built-in concurrent.futures module.
import time
from concurrent.futures import ThreadPoolExecutor
def fetch_data(task_id):
print(f"Starting task {task_id}\n", end="")
time.sleep(1)
print(f"Finished task {task_id}\n", end="")
def main():
start_time = time.time()
# Create a pool of up to 5 worker threads
with ThreadPoolExecutor(max_workers=5) as executor:
# Submit all 5 tasks to the pool
executor.map(fetch_data, range(1, 6))
end_time = time.time()
print(f"Total execution time: {end_time - start_time:.2f} seconds")
if __name__ == "__main__":
main()
Expected Output:
Starting task 1
Starting task 2
Starting task 3
Starting task 4
Starting task 5
Finished task 3
Finished task 1
Finished task 2
Finished task 5
Finished task 4
Total execution time: 1.00 seconds
What Just Happened?
Our execution time dropped from 5 seconds to just 1 second.
When thread 1 hit time.sleep(1), the operating system noticed that thread 1 was blocked and waiting. Instead of pausing the entire program, the operating system instantly performed a context switch over to thread 2.
Thread 2 started executing and also hit time.sleep(1). The operating system immediately switched to thread 3, and so on.
All 5 threads ended up waiting at the exact same time. Their idle waiting periods overlapped perfectly, compressing our total runtime down to the duration of a single task.
Understanding the GIL
If threading is so fast and lightweight, why don't we just use it for absolutely everything?
The answer lies in Python's infamous Global Interpreter Lock, commonly known as the GIL.
The standard, most widely used implementation of Python is written in C and is called CPython. CPython manages memory using a system called reference counting. Every time you create an object, Python keeps track of how many variables are pointing to it. If that count hits zero, Python safely deletes the object from memory.
The problem is that if multiple threads try to increase or decrease this reference count at the exact same time, the count can become corrupted. This leads to leaked memory or, worse, your program crashing because it deleted an object that was still in use.
To protect your data, CPython introduces the GIL. The GIL is a master lock that ensures only one thread can execute Python bytecode at any given millisecond.
Your CPU can only drink from one Python straw at a time. Throwing more threads at a CPU-bound problem is often like hiring more people to use the same single-lane road.
Let us prove this with an experiment. We will write a CPU-bound task, which is a task that does heavy computational calculations and never pauses for network or disk I/O. We will count down from a large number.
import time
from concurrent.futures import ThreadPoolExecutor
COUNT = 20_000_000
def count_down(n):
while n > 0:
n -= 1
def run_sequential():
start = time.time()
count_down(COUNT)
count_down(COUNT)
print(f"Sequential CPU-bound time: {time.time() - start:.2f} seconds")
def run_threaded():
start = time.time()
with ThreadPoolExecutor(max_workers=2) as executor:
executor.submit(count_down, COUNT)
executor.submit(count_down, COUNT)
print(f"Threaded CPU-bound time: {time.time() - start:.2f} seconds")
if __name__ == "__main__":
run_sequential()
run_threaded()
Expected Output:
Sequential CPU-bound time: 1.45 seconds
Threaded CPU-bound time: 1.51 seconds
Analyzing the Results
The threaded version actually took longer than the sequential version.
Because of the GIL, the two threads could not run in parallel on separate CPU cores. Instead, the operating system had to constantly pause one thread, save its state, swap in the second thread, let it count for a microsecond, and swap it back.
This constant swapping adds administrative overhead without providing any performance benefits. If you have heavy math, data processing, or image manipulation to do, standard Python threads will not help you.
Understanding Multiprocessing
To bypass the GIL entirely, we must use multiprocessing.
While threading creates multiple lines of execution inside a single process, multiprocessing spawns completely separate, independent processes.
Each individual process gets its own dedicated private memory space and, crucially, its own separate Python interpreter and GIL.
Because each process has its own interpreter, they can run truly in parallel across different physical cores of your computer's CPU.
Let us rewrite our heavy counting task using ProcessPoolExecutor from the concurrent.futures module.
import time
from concurrent.futures import ProcessPoolExecutor
COUNT = 20_000_000
def count_down(n):
while n > 0:
n -= 1
def main():
start_time = time.time()
# Spin up 2 separate processes
with ProcessPoolExecutor(max_workers=2) as executor:
executor.submit(count_down, COUNT)
executor.submit(count_down, COUNT)
end_time = time.time()
print(
f"Multiprocessing CPU-bound time: {end_time - start_time:.2f} seconds")
if __name__ == "__main__":
main()
Expected Output:
Multiprocessing CPU-bound time: 0.86 seconds
The runtime dropped significantly. Because we used multiprocessing, Python sent one calculation task to Process A on CPU Core 0, and the second calculation task to Process B on CPU Core 1. Both cores worked at maximum capacity simultaneously.
However, this raw speed comes with a significant engineering trade-off: memory isolation.
Because processes do not share memory, you cannot easily modify a global variable in one process and see the change in another. If a process needs to send data back to the main program, Python must serialize the data (convert it into raw bytes), send it over a communication channel, and deserialize it back into a Python object. This operation adds noticeable memory and performance overhead.
Understanding Asyncio
Now let us look at the third option: asyncio.
Asyncio stands for Asynchronous Input/Output. It takes a radically different path to concurrency than threading or multiprocessing.
Instead of relying on the operating system to manage and swap tasks, asyncio handles concurrency entirely inside your application code using a single thread. It achieves this through a mechanism called the Event Loop.
Think of the event loop as a manager running a loop that monitors a list of registered tasks.
To use asyncio, you declare your functions using the async keyword, turning them into coroutines. Inside a coroutine, when you reach a slow operation (like a network request), you use the await keyword to hand control directly back to the event loop.

Let us write a runnable example using Python's built-in asyncio library.
import asyncio
import time
# 'async def' tells Python this is a coroutine, not a regular function
async def fetch_data(task_id):
print(f"Starting task {task_id}")
# 'await' yields control back to the event loop
await asyncio.sleep(1)
print(f"Finished task {task_id}")
async def main():
start_time = time.time()
# Create a list of coroutine tasks
tasks = [fetch_data(i) for i in range(1, 6)]
# Run all tasks concurrently on the event loop
await asyncio.gather(*tasks)
end_time = time.time()
print(f"Total execution time: {end_time - start_time:.2f} seconds")
if __name__ == "__main__":
# Start the asyncio event loop
asyncio.run(main())
Expected Output:
Total execution time: 1.01 seconds
Our script processed all 5 tasks in 1 second, completely inside a single thread.
When fetch_data(1) executed await asyncio.sleep(1), it explicitly paused itself and told the event loop: "I am going to be waiting for 1 second. Go ahead and run something else."
The event loop checked its list, saw fetch_data(2), and started it immediately. No threads were created, meaning the operating system did not have to deal with heavy context switching overhead.
Threading vs Asyncio for API Calls
Backend engineers frequently debate whether to use threading or asyncio when building systems that make hundreds of external HTTP API calls. Both handle I/O-bound workloads efficiently, but they do it differently.
The Technical Differences
Threading uses cooperative or preemptive multitasking managed by the operating system. You can use standard, synchronous libraries like requests. However, each thread consumes roughly 8MB of memory by default. If you try to spin up 10,000 threads simultaneously, your server will likely run out of RAM and crash.
Asyncio uses explicit cooperative multitasking managed entirely by your code. Because everything runs in a single thread, an individual coroutine task consumes less than 1KB of memory. You can easily run 10,000 or even 50,000 async tasks concurrently on a modest server.
The catch? You cannot use requests inside asyncio because requests is a blocking library. It will lock up the entire single-threaded event loop, stopping every other task in its tracks. You must use asynchronous libraries like httpx or aiohttp.
Which One Should You Choose?
If you are modifying an existing codebase that relies heavily on synchronous libraries, or if you only need to run a few dozen tasks, threading is usually simpler and faster to implement.
If you are building a modern, high-throughput backend service from scratch (like a FastAPI application) that needs to maintain thousands of concurrent connections or scrapers, asyncio is the industry standard choice.
The Concurrency Matrix
Feature | Threading | Multiprocessing | Asyncio |
Best Use Case | Web scraping, low-volume I/O | Heavy calculations, data processing | High-scale APIs, WebSockets |
Workload Type | I/O-bound | CPU-bound | I/O-bound |
Memory Usage | Moderate (Megabytes per thread) | High (Each process copies memory) | Low (Kilobytes per coroutine) |
Code Complexity | Low to medium | Medium | High (Requires async/await everywhere) |
Scalability | Hundreds of concurrent tasks | Limited by available CPU cores | Tens of thousands of concurrent tasks |
GIL Impact | Kept in place (Limits execution) | Bypassed entirely | Kept in place (Unimpacted by single thread) |
Ease of Debugging | Hard (Race conditions can happen) | Medium (Isolated state) | Hard (Stack traces can be cryptic) |
Explaining the Rows
Workload Type & Best Use Cases
Threading and asyncio are tailored specifically for I/O tasks where your code spends time waiting on external networks or disks. Multiprocessing is reserved for intensive computations where your CPU cores are working at 100% capacity.
Memory Usage & Scalability
Because processes run entirely separate interpreters, they have the heaviest memory footprint. Threads require a fixed chunk of memory from the operating system, limiting them to hundreds or thousands of instances. Asyncio coroutines are simple objects in memory, allowing you to scale up to tens of thousands of tasks without breaking a sweat.
Code Complexity & Debugging
Threading allows you to use normal Python code, but sharing data between threads introduces subtle bugs called race conditions. Multiprocessing avoids this via isolated memory, but it makes passing data between tasks more complex. Asyncio requires you to change your entire coding style to use async/await, meaning a single synchronous function call can unexpectedly stall your system.
Real-World Backend Engineering Examples
Let us look at how backend teams map these tools to specific production infrastructure workloads.
1. When to Use Threading
Legacy Data Migrations: A background cron job that reads a batch of 50 customer profiles from a relational database and writes them to a third-party CRM system.
File Downloader Utilities: A script that reads a list of 100 image URLs and downloads them onto a local drive.
2. When to Use Multiprocessing
Machine Learning & Analytics Pipelines: Tokenizing text datasets or calculating massive matrix transformations before feeding data into a model.
Image Optimization Workers: An upload system that receives high-resolution user photos and resizes them into thumbnails for an e-commerce platform.
3. When to Use Asyncio
Real-Time Chat Operations: Managing thousands of active, long-lived WebSocket connections for a chat application.
High-Performance API Gateways: A service built with FastAPI that acts as a proxy, hitting five microservices concurrently to assemble a single response payload for a frontend application.
When faced with a performance problem, do not guess. Follow this practical engineering decision flow to pick the correct concurrency model:

Common Mistakes to Avoid
1. Blocking the Asyncio Event Loop
The most frequent production failure in asyncio applications happens when developers use blocking functions inside an asynchronous code path.
# ANTI-PATTERN
async def handle_request():
# This completely freezes the entire backend server for 2 seconds!
time.sleep(2)
return {"status": "done"}
The Fix: Always use the non-blocking equivalent (await asyncio.sleep(2)) or delegate the blocking call to a thread pool using asyncio.to_thread().
2. Using Threads for Heavy Calculations
Developers often wrap heavy math operations in threads, assuming it will make them run faster. As we proved in our GIL section, the administrative cost of context switching will actually slow your program down. Always use multiprocessing for computational heavy lifting.
Never implement a complex concurrency architecture based on assumptions. Always use a tool like Python's built-in time module or a profiler to measure your code first. Identify where the actual bottleneck is before writing a single line of concurrent code.
Key Takeaways
Concurrency vs Parallelism: Concurrency is about structuring your code to handle multiple tasks efficiently. Parallelism is about physically executing tasks at the exact same millisecond across multiple CPU cores.
The Python GIL: The Global Interpreter Lock ensures that only one thread executes Python bytecode at a time inside a standard CPython process.
Threading lets you handle multiple I/O-bound tasks by overlapping their idle wait states. It shares memory by default but is limited by the GIL.
Multiprocessing completely bypasses the GIL by spawning isolated Python processes across different CPU cores, making it the perfect choice for computational work.
Asyncio offers high-performance, single-threaded concurrency for I/O-bound tasks using an event loop, making it highly scalable but requiring a specific async library ecosystem.