RabbitMQ vs Kafka: Key Differences, Trade-offs, and When to Use Each
A practical guide to understanding the architectural decisions behind RabbitMQ and Kafka, not just their features.

If you hang around software engineering circles, you will inevitably hear a heated debate: "Should we use RabbitMQ or Kafka?" It’s a question asked in architecture review boards, system design interviews, and Reddit threads. But it is fundamentally the wrong question.
Asking "RabbitMQ vs Kafka" is like asking "Should I buy a minivan or a dump truck?" Both are vehicles. Both have wheels. Both transport things. But they were engineered to solve entirely different problems.
Treating them as direct competitors leads to fragile architectures, frustrated developers, and costly production incidents. To truly master distributed systems, we must stop comparing their features in a vacuum and start understanding why they were created, the distinct architectural philosophies they embody, and the operational realities that dictate their use.
Before RabbitMQ and Kafka: The Original Problem
Before we look at the solutions, we must understand the problem. Think about a classic, monolithic application. When a user buys a product, the code to charge the credit card, update the inventory, and send a confirmation email all runs in the same process. It is a synchronous, tightly coupled flow.
As systems scale and break into microservices, this synchronous flow becomes a nightmare. If the Checkout Service calls the Email Service directly via HTTP:
Tight Coupling: The
Checkout Serviceneeds to know the exact address and API of theEmail Service.Cascading Failures: If the
Email Servicegoes down, theCheckout Servicemight time out, failing the entire user order just because an email couldn't be sent.Backpressure Issues: If the
Email Servicecan handle 10 requests per second, but a Black Friday sale generates 100 orders per second, theEmail Servicecrashes under the load.
Engineers needed a way to decouple systems. They needed asynchronous communication. They needed an intermediary, a Message Broker, that could accept a message from a producer, hold onto it safely, and deliver it to a consumer at the consumer's own pace.
This is the genesis of message brokering. But how you broker those messages depends entirely on what you prioritize.
Understanding RabbitMQ: The Smart Broker
The History and Philosophy
In the mid-2000s, the financial industry had a problem. They needed to move millions of messages reliably between disparate, heterogeneous systems. Existing solutions were proprietary, expensive, and locked them into specific vendors.
Enter AMQP (Advanced Message Queuing Protocol), an open standard designed to create a universal language for messaging. RabbitMQ, created in 2007 and written in Erlang (a language built for highly concurrent, fault-tolerant telecommunications), emerged as the premier implementation of AMQP.
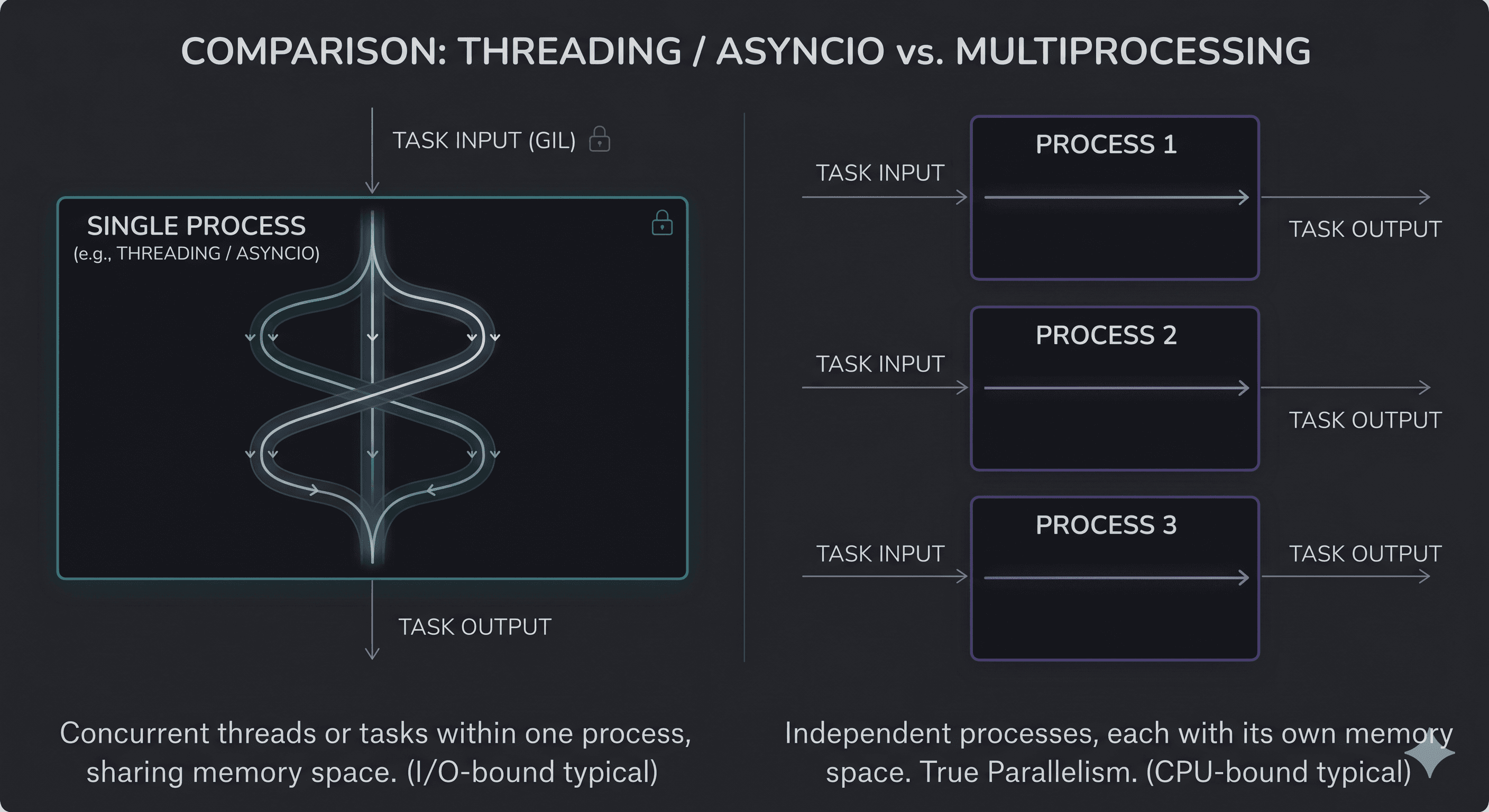
RabbitMQ’s core philosophy is "Smart Broker, Dumb Consumer." The broker takes on the heavy lifting of routing messages, tracking who has consumed what, and ensuring reliable delivery. The consumers just connect, ask for work, and process it.
Core Architecture

RabbitMQ operates on a highly flexible routing model:
Producers never publish directly to a queue. They publish to an Exchange.
Exchanges act like a post office sorting facility. Based on the rules (Bindings), the exchange routes copies of the message to one or more Queues.
Queues store the messages until they are processed.
Consumers receive messages from the queues, process them, and send an Acknowledgement (ACK).
The "Why" Behind RabbitMQ's Design Choices
Why Exchanges? Because routing logic shouldn't be hardcoded into producers or consumers. If you want a message to go to one service today and three services tomorrow, you just change the broker's binding rules. The producer code never changes.
Why a "Push" Model? RabbitMQ pushes messages to consumers. To prevent overwhelming a consumer, it uses a Prefetch Limit (e.g., "only push 5 unacknowledged messages at a time"). This is how RabbitMQ elegantly handles backpressure.
Why Acknowledgements? RabbitMQ deletes a message only after a consumer explicitly says, "I have successfully processed this." If a consumer crashes mid-processing, RabbitMQ detects the severed connection and re-queues the message for another worker. This guarantees work is never lost.
Why does it excel at Task Distribution? RabbitMQ implements the Competing Consumers pattern perfectly. If you have a queue with 10,000 background jobs, you can attach 50 consumers to it, and RabbitMQ will safely deal them out round-robin style.
Why does it avoid Head-of-Line Blocking? Imagine a single-lane drive-thru. If the first car orders 50 custom burgers, the 10 cars behind them waiting for a simple coffee are stuck. That is Head-of-Line blocking. Because RabbitMQ deals messages out to a pool of workers, a slow task doesn't block fast tasks from being processed by other consumers.
💡 System Design Interview Tip: When an interviewer asks you to design a system with long-running, isolated tasks (like generating a PDF or processing a video), immediately reach for a message queue like RabbitMQ. Mention the "Competing Consumers" pattern and message acknowledgements for fault tolerance.
Understanding Kafka: The Distributed Log
The History and Philosophy
Around 2010, LinkedIn hit a wall. They were generating massive amounts of data - page views, clicks, profile updates, search queries. They needed to move this firehose of data from their frontend servers to their backend analytics systems, recommendation engines, and Hadoop clusters.
Traditional message brokers like RabbitMQ were choking. Why? Because RabbitMQ tracks the state of every single message for every single consumer. When you push millions of messages per second, the overhead of tracking individual ACKs and deleting individual messages becomes a massive bottleneck.
LinkedIn engineers realized they didn't need a traditional queue. They needed a high-throughput pipeline. So, they built Apache Kafka.
Kafka’s core philosophy is "Dumb Broker, Smart Consumer." Kafka doesn't track what you have read. It doesn't route messages dynamically. It just acts as a massive, highly optimized, distributed append-only log.
Core Architecture

Events are written to a Topic.
Topics are split into Partitions, which are distributed across multiple servers (Brokers) for massive horizontal scale.
Kafka writes messages sequentially to disk (an Append-only Log).
Consumers explicitly request to read messages sequentially.
Instead of the broker deleting a message when read, the consumer remembers its position in the log, an Offset.
The "Why" Behind Kafka's Design Choices
Why an Append-Only Log? Hard drives are incredibly fast at sequential writes, but slow at random reads/writes. By only appending to the end of a file and never modifying/deleting individual records, Kafka achieves RAM-like speed using cheap disk storage.
What is "Zero-Copy I/O"? Kafka utilizes an OS-level optimization called Zero-Copy. Instead of loading data from the disk into the application's memory just to send it over the network, Kafka streams the data directly from the OS disk cache to the network socket. This is a massive reason for its million-message-per-second throughput.
Why a "Pull" Model? Kafka consumers poll (pull) the broker for data. Why? Because in big data pipelines, batching is everything. By pulling, consumers can dictate their own consumption rate and grab hundreds of messages in a single network request, maximizing throughput.
Why do Consumers track Offsets? By offloading the state-tracking to the consumers, the broker doesn't care if 1 consumer or 100,000 consumers are reading the log. The broker’s workload remains exactly the same. Decentralizing state is the secret to infinite scale.
Why Partitions? A single log file can only be as big or fast as a single hard drive. By partitioning a topic, Kafka spreads the log across hundreds of machines, allowing parallel writes and reads.
The Deep Architectural Difference: Message vs. Event
To truly master these systems, you must internalize this single, profound difference:
RabbitMQ embodies the "Message Queue" mindset.
A message is a command. It is transient. It is an envelope saying, "Hey, please do this work." Once the work is done, the message has fulfilled its destiny, and it is destroyed.
- Analogy: RabbitMQ is a Post Office. The letter arrives, the mail carrier delivers it to your mailbox, you open it, and you throw the envelope away.
Kafka embodies the "Distributed Log" mindset.
An event is a fact. It is persistent. It is a historical record saying, "This thing happened in the past." You cannot delete history.
- Analogy: Kafka is a public ledger or a history book. Anyone can read chapter 1, at any time, as many times as they want. Reading the book doesn't make the pages disappear.
RabbitMQ vs Kafka: Feature Comparison Table
Feature | RabbitMQ (Message Queue) | Kafka (Event Log) | Why? |
Data Retention | Ephemeral | Persistent | Queues empty out when work is done. Logs store history. |
Consumer Model | Push (with prefetch) | Pull (Polling) | RMQ distributes tasks immediately. Kafka lets big-data consumers optimize batches. |
Message State | Tracked by Broker (ACKs) | Tracked by Consumer (Offsets) | Centralized state enables complex routing/retries. Decentralized state scales infinitely. |
Routing | Highly complex (Exchanges) | Simple (Topic/Partition) | RMQ routes workflows dynamically. Kafka relies on producers putting events in the right topic. |
Delivery Semantics | At-Least-Once | Exactly-Once (via Tx APIs) | Kafka's ecosystem allows transactional end-to-end processing. RMQ requires idempotent consumers. |
Replayability | No | Yes (Time-travel via offsets) | You can't un-deliver mail. But you can re-read a history book. |
Note: RabbitMQ recently introduced "Streams" which behave similarly to Kafka's append-only logs, showing that modern tools often borrow the best ideas from each other. However, RabbitMQ's primary identity remains a traditional message broker.
The Operational Reality Check: Failures and Idempotency
Architectural theory is beautiful, but production is messy. If you are preparing for a senior engineering interview, you must understand the operational failure modes of these systems.
1. At-Least-Once Delivery and the Need for Idempotency
Whether you use RabbitMQ or Kafka, networks are unreliable. Imagine a RabbitMQ consumer processes an e-commerce order, charges the customer's credit card, but then the server's network cable is cut before it can send the ACK back to RabbitMQ.
RabbitMQ assumes the consumer died and requeues the message. Another consumer picks it up and charges the customer again.
The Fix: You must design your consumers to be Idempotent. This means applying the same message multiple times has the same effect as applying it once. You achieve this by storing a unique order_id in your database and checking if you've already processed it before charging the card. Do not rely on the broker to save you from duplicate processing.
2. Poison Messages and Dead Letter Queues (DLQ)
What happens if a message payload is corrupted (a "poison message")?
In RabbitMQ: The consumer throws an error, rejects the message, and RabbitMQ gracefully routes it to a Dead Letter Queue for developers to inspect later. The next message in the queue processes normally.
In Kafka: Because consumers read sequentially from a partition, a consumer crashing on Offset 5 means it will reboot, read Offset 5 again, and crash again. Forever. This blocks the entire partition. Implementing DLQs in Kafka requires you to manually catch the error, write the bad message to a separate "retry topic", and manually advance your offset. It is significantly more complex.
3. Scaling and Rebalancing Latency
In RabbitMQ: If you have 50 workers and add a 51st, RabbitMQ simply starts dealing cards to the new worker. It is seamless and instant.
In Kafka: A single partition can only be read by one consumer in a group to guarantee order. If you have 10 partitions, you can have a maximum of 10 consumers. If you add a new consumer, Kafka must perform a Consumer Group Rebalance. It pauses processing, recalculates who gets which partition, and starts back up. This can cause severe latency spikes in production.
System Design Interview Perspective
In a system design interview, choosing the wrong message broker is a major red flag.
When to choose RabbitMQ:
"I need to run background tasks." (e.g., Image processing).
"I need complex routing." (e.g., If user is VIP, send to Queue A; else Queue B).
"Tasks have varying processing times." (Because RabbitMQ doesn't suffer from Head-of-Line blocking).
"I need precise, individual message retries and Dead Letter tracking."
"I need strict ordering but with dynamic scaling." (Mention using RabbitMQ's Consistent Hash Exchange).
When to choose Kafka:
"I have massive throughput requirements." (e.g., IoT telemetry, clickstreams).
"I need strict chronological ordering of events." (e.g., Applying database updates/CDC in exact order).
"Multiple independent services need to react to the same data." (e.g., A user signs up: Auth, Recommendations, and Analytics all need to know).
"I need to replay history to rebuild state or train a new ML model."
⚠️ Common Interview Trap: Candidates often say, "I'll use Kafka because it's faster and more modern." Interviewers will instantly ask how you plan to handle individual message retries or poison messages. If you don't know the complexity of Kafka error handling, stick to RabbitMQ for operational tasks.
Real Production Scenarios
Scenario 1: Background Job Processing
The Job: You run a platform where users upload videos. You need to transcode these videos.
The Choice: RabbitMQ.
The Reasoning: Video transcoding takes time (minutes to hours). If you used Kafka, a 4-hour 4K video transcode would block all other videos in that partition. With RabbitMQ, you spin up a pool of worker nodes.
Scenario 2: E-Commerce Checkout System
The Job: A user clicks "Buy." You must process payment, reserve inventory, and send a receipt.
The Choice: RabbitMQ (for the operational workflow).
The Reasoning: This is a transactional workflow. You need exact retries. If the payment gateway API times out, you want to retry just that specific message with exponential backoff. RabbitMQ's DLXs are perfect for this (paired with idempotent consumers!).
Scenario 3: Real-Time Analytics Pipeline
The Job: You need to track every button click, mouse movement, and page transition from a million concurrent users.
The Choice: Kafka.
The Reasoning: Throughput. RabbitMQ would collapse under the sheer volume of ACKs required for millions of clicks per second. Kafka streams these events to disk sequentially, allowing your analytics engine to consume them in massive batches.
Scenario 4: Event Sourcing & Audit Logs
The Job: You are building a banking application. You must store every single transaction (Deposit $10, Withdraw $5) so you can independently verify the balance from scratch.
The Choice: Kafka.
The Reasoning: You need immutable history and replayability. If an auditor comes in, you point a new consumer at Offset 0 of the
transactionstopic, and it reads years of history to verify the ledger.
Why Companies Often Use Both
One of the biggest misconceptions is that a company must standardize on either RabbitMQ or Kafka. In reality, almost all large-scale tech companies use both, playing to their respective strengths.
Consider a modern architecture for a food delivery platform:

The Operational Workflow: The immediate tasks (charging the card, pinging the restaurant's tablet) are handled by RabbitMQ. It acts as the nervous system, managing the state of the work.
The Data Pipeline: As those workers complete their jobs, they emit "facts" (e.g., "Order #123 Paid") into Kafka. Kafka acts as the corporate memory, holding these events forever so the Data Science team can train machine learning models.
They are entirely complementary. RabbitMQ coordinates the present. Kafka records the past.
The Decision Framework
If you find yourself paralyzed by choice in a project, use this simplified decision tree:
Do you need to replay messages from the past?
- Yes → Kafka.
Are you routing messages based on complex rules (wildcards, headers)?
- Yes → RabbitMQ.
Do you need massive throughput (100k+ events/sec) or stream processing?
- Yes → Kafka.
Do tasks take varying amounts of time, requiring individual retries and Dead Letter tracking?
- Yes → RabbitMQ.
Do I lack a dedicated platform engineering team to manage complex infrastructure?
- Yes → RabbitMQ (Kafka's operational overhead with KRaft/Zookeeper is significant).
Final Takeaway
As an architect or senior engineer, your job is not to memorize feature matrices. Your job is to deeply understand the underlying paradigms of the tools at your disposal so you can align them with the contours of your specific business problem.
If you remember nothing else from this article, remember this fundamental principle:
"RabbitMQ is primarily optimized for delivering work. Kafka is primarily optimized for preserving events."
Design your systems accordingly.