Who Are The Top Richest Persons Around The World?

Introduction
Do you know who is the richest person in the world? I'm sure you know him.

Yes, Elon Musk is the richest person in the world. But do you know who are the other top richest persons around the world?
Let's scape the Bloomberg Billionaires Index to know who are the top richest persons around the world. After scraping, we will generate a CSV as well as JSON file with the data.
Get Your Tools Ready
First things first, make sure you have Python 3 installed on your system. If not, install it from here.
We'll be using a few libraries to get our work done. Some of them are pre-installed with Python while some are external libraries that we are required to install.
- Beautiful Soup: It is a Python library for pulling data out of HTML and XML files. To install it, run the following command:
pip install beautifulsoup4
- Selenium: It is a powerful tool for controlling web browsers programmatically. To install it, run the following command:
pip install selenium
To work with Selenium, we will require a webdriver for our browser. WebDriver drives a browser natively, as a user would, either locally or on a remote machine using the Selenium server. The webdrivers are version-specific. You can install ChromeDriver from here according to your browser version. For this tutorial, I'll be using Google Chrome version 100.0.4896.75. After you download the ChromeDriver, put the file in your working directory.
Let's Scrape It!
First, let's have a look at the webpage that we're going to scrape located at https://www.bloomberg.com/billionaires/. It contains the data of the Top 500 Richest Persons around the world. The page is updated daily. Since the data on the webpage is being loaded using Javascript, we won't be able to use the requests library. That's why we are using Selenium to load the page.
import csv
import json
from bs4 import BeautifulSoup
from selenium import webdriver
BROWSER = webdriver.Chrome(executable_path="chromedriver.exe")
TOTAL_PERSONS = 100
def data_scraper():
BROWSER.get("https://www.bloomberg.com/billionaires/")
html_source = BROWSER.page_source
BROWSER.close()
soup = BeautifulSoup(html_source, 'html.parser')
response_rank = soup.find_all('div', class_='table-cell t-rank')
ranks = [rank.get_text().strip() for rank in response_rank][:TOTAL_PERSONS]
response_name = soup.find_all('div', class_='table-cell t-name')
names = [name.get_text().strip() for name in response_name][:TOTAL_PERSONS]
links = [(name.find('a')['href']).replace("./", "") for name in response_name]
response_worth = soup.find_all('div', class_='table-cell active t-nw')
worths = [worth.get_text().strip()
for worth in response_worth][1:TOTAL_PERSONS+1]
response_last_change = soup.find_all('div', class_='t-lcd')
last_changes = [change.get_text().strip()
for change in response_last_change][1:TOTAL_PERSONS+1]
response_ytd = soup.find_all('div', class_='t-ycd')
ytds = [ytd.get_text().strip() for ytd in response_ytd][1:TOTAL_PERSONS+1]
response_country = soup.find_all('div', class_='table-cell t-country')
countries = [country.get_text().strip()
for country in response_country][1:TOTAL_PERSONS+1]
response_industry = soup.find_all('div', class_='table-cell t-industry')
industries = [industry.get_text().strip()
for industry in response_industry][1:TOTAL_PERSONS+1]
data_dict = {
"ranks": ranks,
"names": names,
"links": links,
"worths": worths,
"last_changes": last_changes,
"ytds": ytds,
"countries": countries,
"industries": industries
}
return data_dict
if __name__ == '__main__':
data = data_scraper()
print(data)
First of all, we have declared two global variables BROWSER and TOTAL_PERSONS. Since I am using Google Chrome, I have used drive.Chrome() with the executable path for chromedriver.exe. The TOTAL_PERSONS variable refers to the number of persons we wish to get data.
We have defined a function data_scraper() that will scrape the data. Inside the function, first we will open the webpage using our BROWSER and get the page source, i.e., the HTML of the page. The HTML code is stored in a variable html_source and the BROWSER is closed. Using the html_source, we create a soup using BeautifulSoup library.
Now let's look at the HTML code and see what all data we need. Inspect the webpage to view the HTML code of the page.
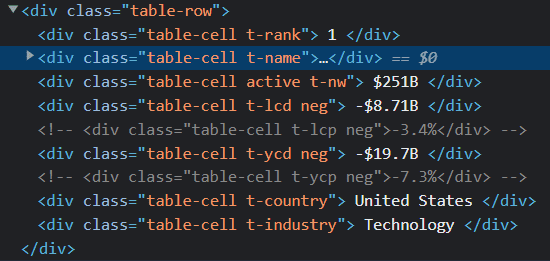
If you see in the above image, we have seven div elements with their classes. We can extract our data using these classes. Suppose, we want to extract all the ranks, we can use the soup.find_all() command with the tag name and class name. We can use the below code:
response_rank = soup.find_all('div', class_='table-cell t-rank')
ranks = [rank.get_text().strip() for rank in response_rank][:TOTAL_PERSONS]
Similarly we have extracted other data like name, net worth, last changes, yesterday changes, country and industry. WIth all the data extracted, we have created a data_dict dictionary and returned it.
In the main function, we have just called the data_scraper() function. If you wish, you can print the data to see how it looks like.
Convert to CSV File
Since we have extracted all the data, we can now put this data into a CSV file for further usage. Let's see how we can do it.
import csv
def write_to_csv(data: dict) -> None:
columns = ['Rank', 'Name', 'Link',
'Total net worth($)', '$ Last change', '$ YTD change', 'Country/Region', 'Industry']
with open(f"top-{TOTAL_PERSONS}-persons.csv", "w", newline="") as csv_file:
writer = csv.DictWriter(csv_file, fieldnames=columns)
writer.writeheader()
for i in range(TOTAL_PERSONS):
temp = {
"Rank": data["ranks"][i],
"Name": data["names"][i],
"Link": f"https://www.bloomberg.com/billionaires/{data['links'][i]}",
"Total net worth($)": data["worths"][i],
"$ Last change": data["last_changes"][i],
"$ YTD change": data["ytds"][i],
"Country/Region": data["countries"][i],
"Industry": data["industries"][i]
}
writer.writerow(temp)
We have created a write_to_csv() function that accepts a dictionary as argument. Inside the function, we first create a list of the columns we should have. Then open a csv file to write our data inside it. After that we create a DictWriter with the csv file and columns and write the column header inside it. After that, we iterate and create a temp dictionary with each person data one after another and write it as a row inside the CSV file.
Convert to JSON File
We can also write the data to a JSON file in a similar way.
import json
def write_to_json(data: dict) -> None:
data_list = []
for i in range(TOTAL_PERSONS):
temp = {
"Rank": data["ranks"][i],
"Name": data["names"][i],
"Link": f"https://www.bloomberg.com/billionaires/{data['links'][i]}",
"Total net worth($)": data["worths"][i],
"$ Last change": data["last_changes"][i],
"$ YTD change": data["ytds"][i],
"Country/Region": data["countries"][i],
"Industry": data["industries"][i]
}
data_list.append(temp)
with open(f"top-{TOTAL_PERSONS}-persons.json", "w") as json_file:
json.dump(data_list, json_file)
Inside the write_to_json() function, we first create an empty list data_list. After that, we iterate in the same way as we did before, but this time, we append the temp dictionary to the data_list list. Further we create a JSON file and dump the data into it.
Full Code
We can now call the above two functions inside the main function.
import csv
import json
from bs4 import BeautifulSoup
from selenium import webdriver
BROWSER = webdriver.Chrome(executable_path="chromedriver.exe")
TOTAL_PERSONS = 100
def data_scraper():
BROWSER.get("https://www.bloomberg.com/billionaires/")
html_source = BROWSER.page_source
BROWSER.close()
soup = BeautifulSoup(html_source, 'html.parser')
response_rank = soup.find_all('div', class_='table-cell t-rank')
ranks = [rank.get_text().strip() for rank in response_rank][:TOTAL_PERSONS]
response_name = soup.find_all('div', class_='table-cell t-name')
names = [name.get_text().strip() for name in response_name][:TOTAL_PERSONS]
links = [(name.find('a')['href']).replace("./", "") for name in response_name]
response_worth = soup.find_all('div', class_='table-cell active t-nw')
worths = [worth.get_text().strip()
for worth in response_worth][1:TOTAL_PERSONS+1]
response_last_change = soup.find_all('div', class_='t-lcd')
last_changes = [change.get_text().strip()
for change in response_last_change][1:TOTAL_PERSONS+1]
response_ytd = soup.find_all('div', class_='t-ycd')
ytds = [ytd.get_text().strip() for ytd in response_ytd][1:TOTAL_PERSONS+1]
response_country = soup.find_all('div', class_='table-cell t-country')
countries = [country.get_text().strip()
for country in response_country][1:TOTAL_PERSONS+1]
response_industry = soup.find_all('div', class_='table-cell t-industry')
industries = [industry.get_text().strip()
for industry in response_industry][1:TOTAL_PERSONS+1]
data_dict = {
"ranks": ranks,
"names": names,
"links": links,
"worths": worths,
"last_changes": last_changes,
"ytds": ytds,
"countries": countries,
"industries": industries
}
return data_dict
def write_to_csv(data: dict) -> None:
columns = ['Rank', 'Name', 'Link',
'Total net worth($)', '$ Last change', '$ YTD change', 'Country/Region', 'Industry']
with open(f"top-{TOTAL_PERSONS}-persons.csv", "w", newline="") as csv_file:
writer = csv.DictWriter(csv_file, fieldnames=columns)
writer.writeheader()
for i in range(TOTAL_PERSONS):
temp = {
"Rank": data["ranks"][i],
"Name": data["names"][i],
"Link": f"https://www.bloomberg.com/billionaires/{data['links'][i]}",
"Total net worth($)": data["worths"][i],
"$ Last change": data["last_changes"][i],
"$ YTD change": data["ytds"][i],
"Country/Region": data["countries"][i],
"Industry": data["industries"][i]
}
writer.writerow(temp)
def write_to_json(data: dict) -> None:
data_list = []
for i in range(TOTAL_PERSONS):
temp = {
"Rank": data["ranks"][i],
"Name": data["names"][i],
"Link": f"https://www.bloomberg.com/billionaires/{data['links'][i]}",
"Total net worth($)": data["worths"][i],
"$ Last change": data["last_changes"][i],
"$ YTD change": data["ytds"][i],
"Country/Region": data["countries"][i],
"Industry": data["industries"][i]
}
data_list.append(temp)
with open(f"top-{TOTAL_PERSONS}-persons.json", "w") as json_file:
json.dump(data_list, json_file)
if __name__ == '__main__':
data = data_scraper()
write_to_csv(data)
write_to_json(data)
After you run the file, you will have a CSV as well as JSON file with the required data. You can set the TOTAL_PERSONS according to your requirement. Note that the value must be less than 500.
You can see the sample CSV file and JSON file.
Wrapping Up
In this tutorial, we saw how we can scrape data using Selenium and Beautiful Soup and create CSV and JSON files out of it.
Hope you liked the tutorial.