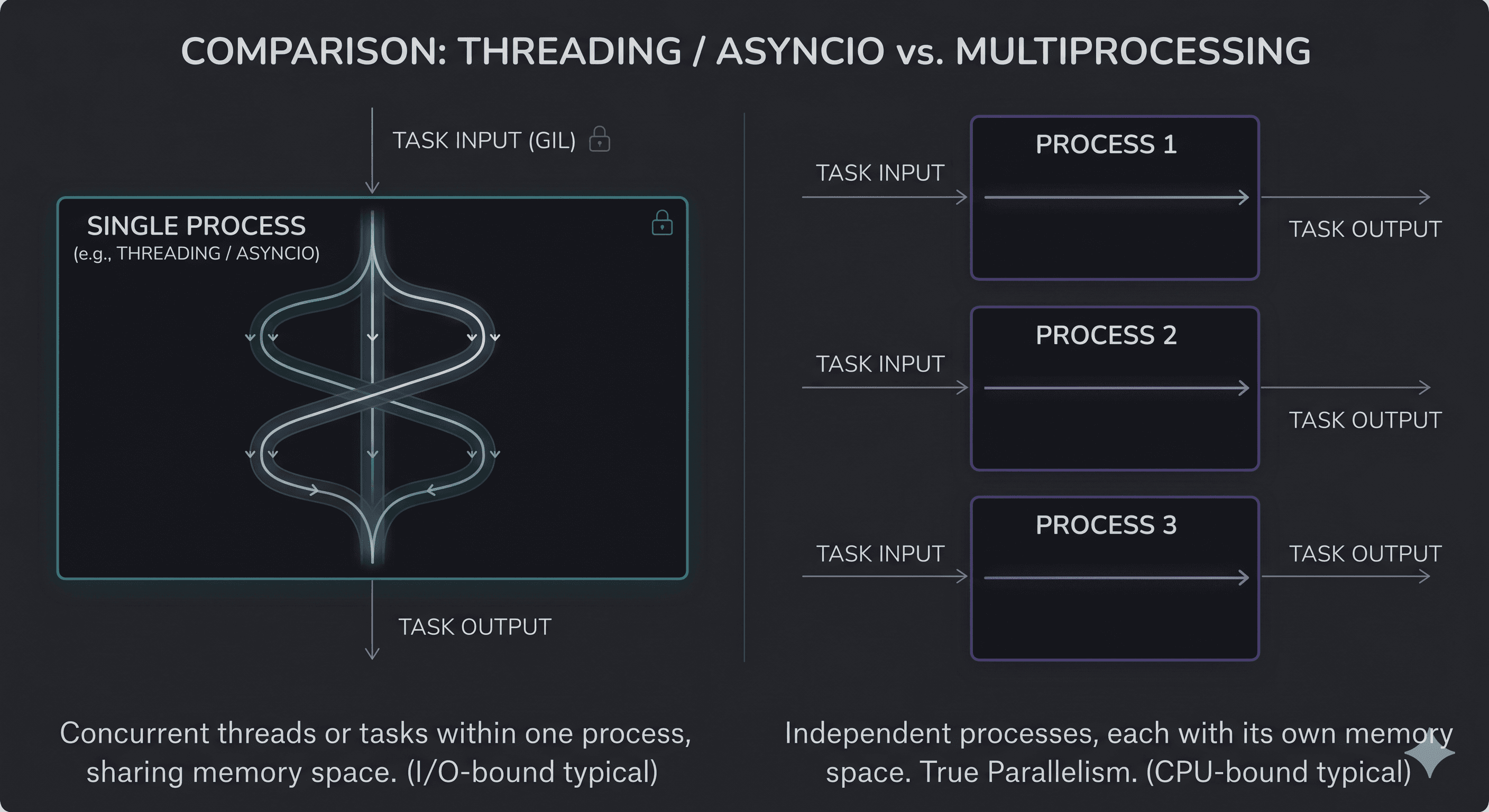
Text to Speech using Web Speech API

Introduction
Voice data is incorporated into online apps using the Web Speech API. In this tutorial, we'll create a simple webpage that implements text-to-speech using the Web Speech API. The Web Speech API's browser compatibility can be found here.
Designing the HTML Page
On the HTML page, we'll have the following things:
- A select menu for selecting voice from the list of available voices
- Range sliders for volume, pitch, and rate
- A
textareato put our content - Control buttons (Start, Pause, Resume, and Cancel)
Now, let us design the webpage. We'll use Bootstrap 5 to style the webpage. Create an index.html file and put the following content there.
<!DOCTYPE html lang="en">
<head>
<link
href="https://cdn.jsdelivr.net/npm/bootstrap@5.1.3/dist/css/bootstrap.min.css"
rel="stylesheet"
integrity="sha384-1BmE4kWBq78iYhFldvKuhfTAU6auU8tT94WrHftjDbrCEXSU1oBoqyl2QvZ6jIW3"
crossorigin="anonymous"
/>
<title>Text To Speech</title>
</head>
<body class="container mt-5 bg-light">
<h1 class="text-dark">Text to Speech</h1>
<div class="row">
<div class="col-md-5">
<p class="lead text-dark mt-4">Select Voice</p>
<!-- Select Menu for Voice -->
<select id="voices" class="form-select text-dark"></select>
</div>
<div class="col-md-1"></div>
<div class="col-md-6">
<!-- Range Slliders for Volume, Rate & Pitch -->
<div class="d-flex mt-4 text-dark">
<div>
<p class="lead">Volume</p>
<input
type="range"
min="0"
max="1"
value="1"
step="0.1"
id="volume"
/>
<span id="volume-label" class="ms-2">1</span>
</div>
<div class="mx-5">
<p class="lead">Rate</p>
<input
type="range"
min="0.1"
max="10"
value="1"
id="rate"
step="0.1"
/>
<span id="rate-label" class="ms-2">1</span>
</div>
<div>
<p class="lead">Pitch</p>
<input type="range" min="0" max="2" value="1" step="0.1" id="pitch" />
<span id="pitch-label" class="ms-2">1</span>
</div>
</div>
</div>
</div>
<!-- Text Area for the User to Type -->
<textarea
class="form-control bg-light text-dark mt-5"
cols="30"
rows="10"
placeholder="Enter text here..."
></textarea>
<!-- Control Buttons -->
<div class="mb-5">
<button id="start" class="btn btn-success mt-5 me-3">Start</button>
<button id="pause" class="btn btn-warning mt-5 me-3">Pause</button>
<button id="resume" class="btn btn-info mt-5 me-3">Resume</button>
<button id="cancel" class="btn btn-danger mt-5 me-3">Cancel</button>
</div>
</body>
<script src="script.js"></script>
The webpage looks like this:

Web Speech API and Its Properties
Let's start by making a SpeechSynthesisUtterance instance. We'll set up several settings for this instance.
let speech = new SpeechSynthesisUtterance();
Now, let’s configure some properties on this SpeechSynthesisUtterance instance.
If you look at the documentation of SpeechSythensisUtterance, you'll find the following six properties associated with it:
1. lang
The lang property gets and sets the language of the utterance. If unset, the <html lang="en"> lang will be used, or the user-agent default if that is unset too. It accepts a DOMString representing a BCP 47 language tag.
speech.lang = "en";
2. pitch
The pitch property gets and sets the pitch at which the utterance will be spoken. It is a float representing the pitch value. It can range between 0 (lowest) and 2 (highest), with 1 being the default pitch for the current platform or voice.
Add a onInput listener to the pitch range slider and modify the pitch property when the slider value changes. The slider's min, max, and default values have already been specified in the HTML tag.
Let's also add a <span> to the homepage that displays the pitch's value next to the range slider.
document.querySelector("#pitch").addEventListener("input", () => {
// Get pitch Value from the input
const pitch = document.querySelector("#pitch").value;
// Set pitch property of the SpeechSynthesisUtterance instance
speech.pitch = pitch;
// Update the pitch label
document.querySelector("#pitch-label").innerHTML = pitch;
});
3. rate
The rate property gets and sets the speed at which the utterance will be spoken. It is a float representing the rate value. It can range between 0.1 (lowest) and 10 (highest), with 1 being the default pitch for the current platform or voice, which should correspond to a normal speaking rate. Other values act as a percentage relative to this, so for example 2 is twice as fast, 0.5 is half as fast, etc.
Let’s add a onInput listener to the rate range slider and adjust the rate property when the value of the slider changes. The slider's min, max, and default values have already been specified in the HTML tag.
Let’s also set the <span> that displays the value of the rate in the webpage next to the range slider.
document.querySelector("#rate").addEventListener("input", () => {
// Get rate Value from the input
const rate = document.querySelector("#rate").value;
// Set rate property of the SpeechSynthesisUtterance instance
speech.rate = rate;
// Update the rate label
document.querySelector("#rate-label").innerHTML = rate;
});
4. text
The text property gets and sets the text that will be synthesized when the utterance is spoken.
The text may be provided as plain text or a well-formed SSML document. The SSML tags will be stripped away by devices that don't support SSML.
Let’s add a click listener to the start button. When the button is clicked, we should get the text value from the textarea and set it to this property.
document.querySelector("#start").addEventListener("click", () => {
speech.text = document.querySelector("textarea").value;
});
5. voice
The voice property gets and sets the voice that will be used to speak the utterance.
This should be set to one of the SpeechSynthesisVoice objects returned by SpeechSynthesis.getVoices(). If not set by the time the utterance is spoken, the voice used will be the most suitable default voice available for the utterance's lang setting.
We need to retrieve the list of available voices in the window object to set the voice of the utterance. The voices will not be available right away when the window object loads. It's an asynchronous operation. When the voices are loaded, an event will be triggered. When the voices are loaded, we can specify a function that should be run.
window.speechSynthesis.onvoiceschanged = () => {
// On Voices Loaded
};
We can get the list of voices using window.speechSynthesis.getVoices(). It’ll return an array of SpeechSynthesisVoice objects that are available. Let’s store the list in a global array voices and update the select menu on the web page with the list of available voices.
let voices = []; // global array
window.speechSynthesis.onvoiceschanged = () => {
// Get List of Voices
voices = window.speechSynthesis.getVoices();
// Initially set the First Voice in the Array.
speech.voice = voices[0];
// Set the Voice Select List. (Set the Index as the value, which we'll use later when the user updates the Voice using the Select Menu.)
let voiceSelect = document.querySelector("#voices");
voices.forEach(
(voice, i) => (voiceSelect.options[i] = new Option(voice.name, i))
);
};
Now that the voice menu has been modified, we can add a onChange event listener to it to update the voice of the SpeechSynthesisUtterance instance. We'll utilize the index number (which is set as the value for each choice) and the global array of voices to update the voice when a user updates it.
document.querySelector("#voices").addEventListener("change", () => {
speech.voice = voices[document.querySelector("#voices").value];
});
6. volume
The volume property gets and sets the volume that the utterance will be spoken. If not set, the default value 1 will be used.
Let’s add an onInput listener to the volume range slider and adjust the volume property when the value of the slider changes. The slider's min, max, and default values have already been specified in the HTML tag.
Let’s also set the <span> that displays the value of the volume in the webpage next to the range slider.
document.querySelector("#volume").addEventListener("input", () => {
// Get volume Value from the input
const volume = document.querySelector("#volume").value;
// Set volume property of the SpeechSynthesisUtterance instance
speech.volume = volume;
// Update the volume label
document.querySelector("#volume-label").innerHTML = volume;
});
Controls
As we know, we'll have four controls: Start, Pause, Resume, and Cancel. Let’s add them to the SpeechSynthesis instance.
1. Start
The SpeechSynthesisUtterance instance should be passed to the window. When the start button is pressed, the window.speechSynthesis.speak() method is invoked. This will begin the process of transforming the text into speech. Before calling this function, the text property must be set.
document.querySelector("#start").addEventListener("click", () => {
speech.text = document.querySelector("textarea").value;
window.speechSynthesis.speak(speech);
});
2. Pause
We can utilize the window.speechSynthesis.pause() to pause the SpeechSynthesisUtterance instance that is currently running. Select the pause button and add a click event listener to it.
document.querySelector("#pause").addEventListener("click", () => {
window.speechSynthesis.pause();
});
3. Resume
Using window.speechSynthesis.resume(), we can resume the SpeechSynthesisUtterance instance that is currently paused. Let's add a click event listener to the resume button and resume the instance when the button is clicked.
document.querySelector("#resume").addEventListener("click", () => {
window.speechSynthesis.resume();
});
4. Cancel
We can use window.speechSynthesis.cancel() to stop the SpeechSynthesisUtterance instance that is currently running. Let's add a click event listener to the cancel button and cancel the instance when the button is clicked.
document.querySelector("#cancel").addEventListener("click", () => {
window.speechSynthesis.cancel();
});
Final Javascript File
Now, our script.js file looks like this:
// Initialize new SpeechSynthesisUtterance object
let speech = new SpeechSynthesisUtterance();
// Set Speech Language
speech.lang = "en";
let voices = []; // global array of available voices
window.speechSynthesis.onvoiceschanged = () => {
// Get List of Voices
voices = window.speechSynthesis.getVoices();
// Initially set the First Voice in the Array.
speech.voice = voices[0];
// Set the Voice Select List. (Set the Index as the value, which we'll use later when the user updates the Voice using the Select Menu.)
let voiceSelect = document.querySelector("#voices");
voices.forEach(
(voice, i) => (voiceSelect.options[i] = new Option(voice.name, i))
);
};
document.querySelector("#rate").addEventListener("input", () => {
// Get rate Value from the input
const rate = document.querySelector("#rate").value;
// Set rate property of the SpeechSynthesisUtterance instance
speech.rate = rate;
// Update the rate label
document.querySelector("#rate-label").innerHTML = rate;
});
document.querySelector("#volume").addEventListener("input", () => {
// Get volume Value from the input
const volume = document.querySelector("#volume").value;
// Set volume property of the SpeechSynthesisUtterance instance
speech.volume = volume;
// Update the volume label
document.querySelector("#volume-label").innerHTML = volume;
});
document.querySelector("#pitch").addEventListener("input", () => {
// Get pitch Value from the input
const pitch = document.querySelector("#pitch").value;
// Set pitch property of the SpeechSynthesisUtterance instance
speech.pitch = pitch;
// Update the pitch label
document.querySelector("#pitch-label").innerHTML = pitch;
});
document.querySelector("#voices").addEventListener("change", () => {
// On Voice change, use the value of the select menu (which is the index of the voice in the global voice array)
speech.voice = voices[document.querySelector("#voices").value];
});
document.querySelector("#start").addEventListener("click", () => {
// Set the text property with the value of the textarea
speech.text = document.querySelector("textarea").value;
// Start Speaking
window.speechSynthesis.speak(speech);
});
document.querySelector("#pause").addEventListener("click", () => {
// Pause the speechSynthesis instance
window.speechSynthesis.pause();
});
document.querySelector("#resume").addEventListener("click", () => {
// Resume the paused speechSynthesis instance
window.speechSynthesis.resume();
});
document.querySelector("#cancel").addEventListener("click", () => {
// Cancel the speechSynthesis instance
window.speechSynthesis.cancel();
});
Result
You can take a look at the project that’s been deployed using GitHub Pages here.
Conclusion
In this blog, we saw how we can use the Web Speech API to convert text to speech. There can be different use-cases for this project. One such is, you can integrate it into your blog site where your users will be able to listen to your article.
You can check out the final code in this GitHub Repository.
Thanks for reading!